Perceiving and manipulating 3D articulated objects (e.g., cabinets, doors) in human environments is an important yet challenging task for future home-assistant robots. The space of 3D articulated objects is exceptionally rich in their myriad semantic categories, diverse shape geometry, and complicated part functionality. Previous works mostly abstract kinematic structure with estimated joint parameters and part poses as the visual representations for manipulating 3D articulated objects. In this paper, we propose object-centric actionable visual priors as a novel perception-interaction handshaking point that the perception system outputs more actionable guidance than kinematic structure estimation, by predicting dense geometry-aware, interaction-aware, and task-aware visual action affordance and trajectory proposals. We design an interaction-for-perception framework VAT-Mart to learn such actionable visual representations by simultaneously training a curiosity-driven reinforcement learning policy exploring diverse interaction trajectories and a perception module summarizing and generalizing the explored knowledge for pointwise predictions among diverse shapes. Experiments prove the effectiveness of the proposed approach using the large-scale PartNet-Mobility dataset in SAPIEN environment and show promising generalization capabilities to novel test shapes, unseen object categories, and real-world data.

Figure 1. Given an input 3D articulated object (a), we propose a novel perception-interaction handshaking point for robotic manipulation tasks - object-centric actionable visual priors, including per-point visual action affordance predictions (b) indicating where to interact, and diverse trajectory proposals (c) for selected contact points (marked with green dots) suggesting how to interact. |
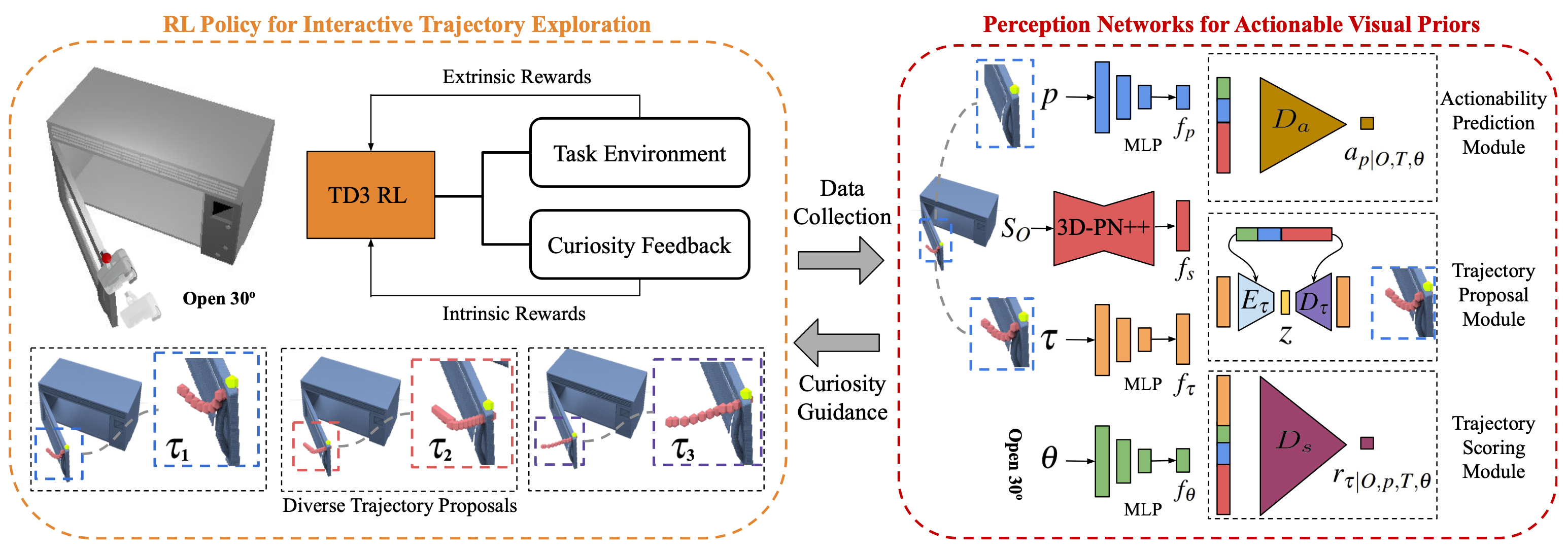
Figure 2. Our proposed VAT-MART framework is composed of an RL policy (left) exploring interaction trajectories and a perception system (right) learning the desired actionable visual priors. We build bidirectional supervisory channels between the two parts: 1) the RL policy collects data to supervise the perception system, and 2) the perception system produces curiosity feedbacks encouraging the RL networks to explore diverse solutions. |
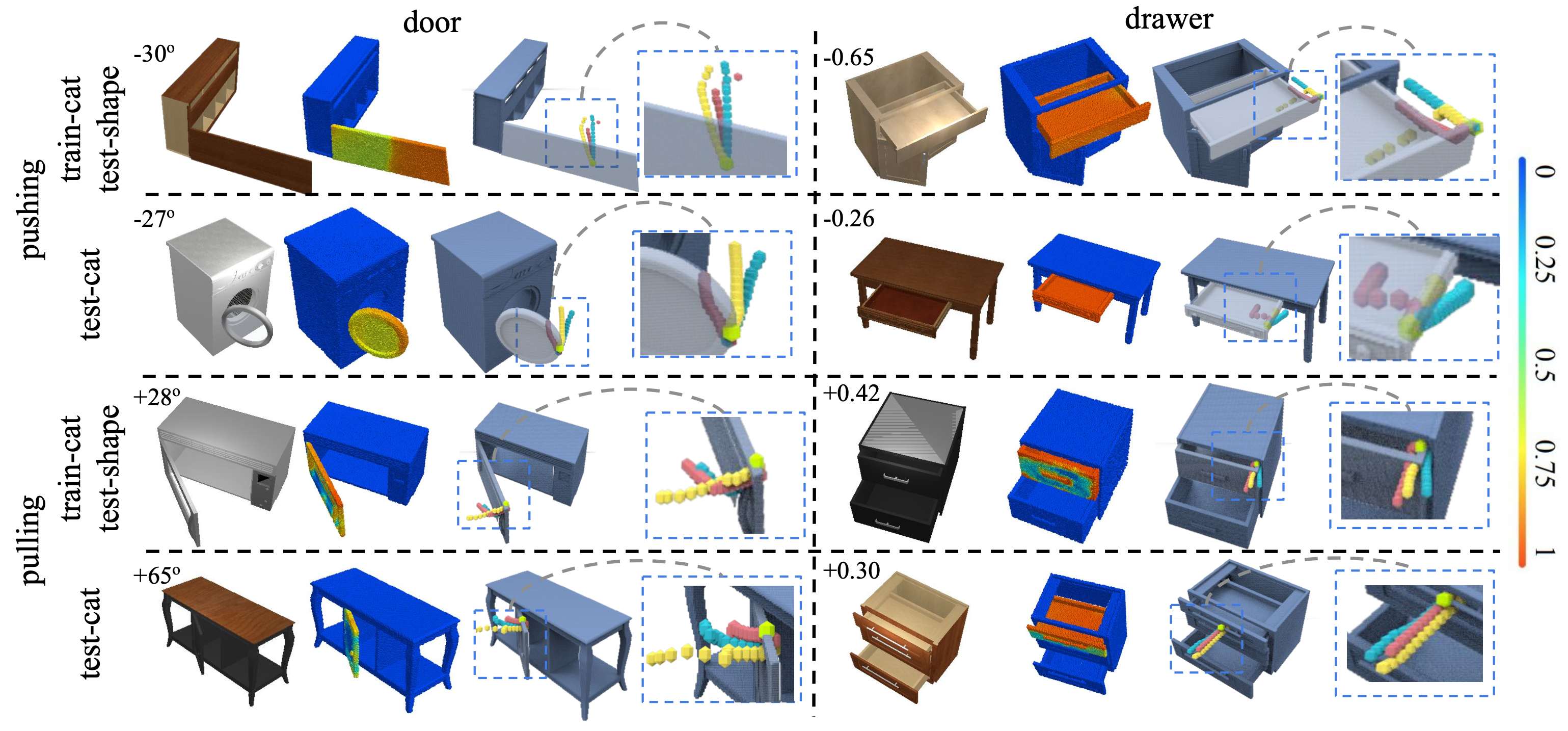
Figure 3. We show qualitative results of the actionability prediction and trajectory proposal modules. In each result block, from left to right, we present the input shape with the task, the predicted actionability heatmap, and three example trajectory proposals at a selected contact point. |
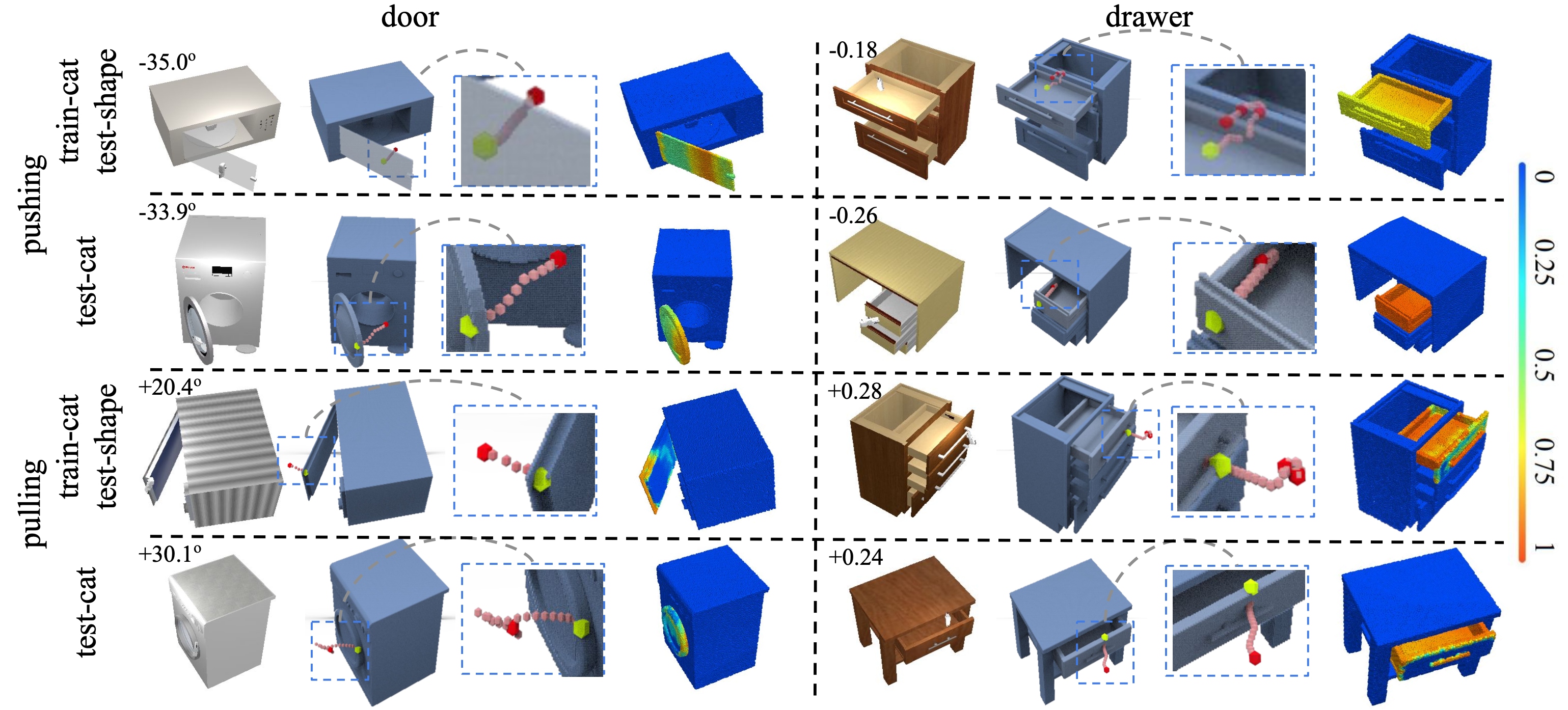
Figure 4. We present qualitative analysis of the learned trajectory scoring module. In each result block, from left to right, we show the input shape with the task, the input trajectory with its close-up view, and our network predictions of success likelihood applying the trajectory over all the points. |
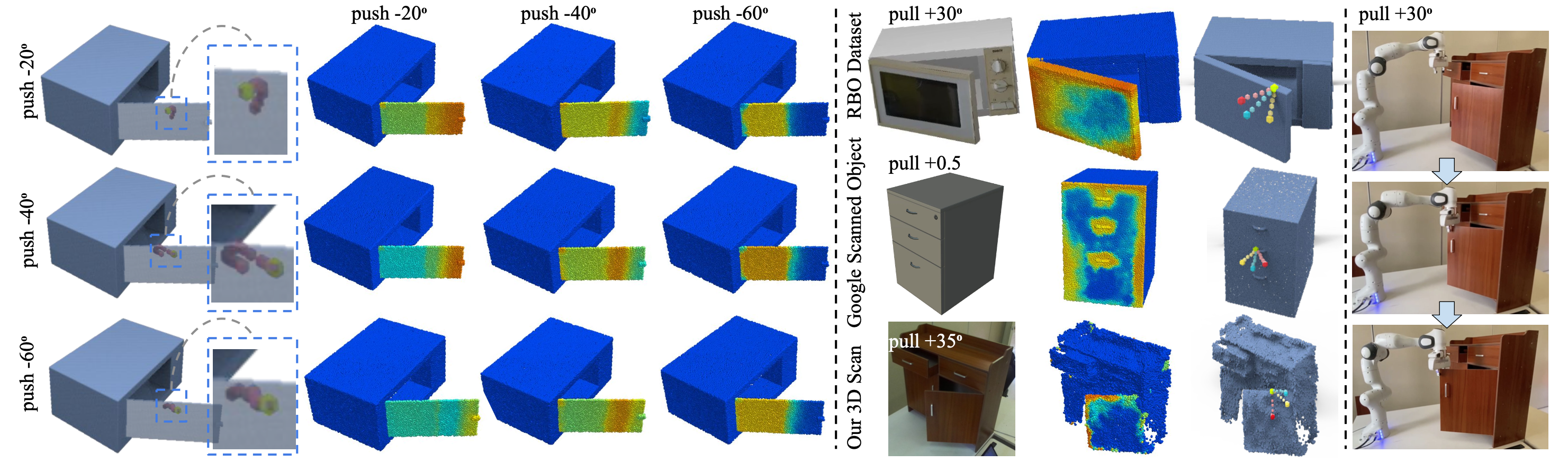
Figure 5. Left: qualitative analysis of the trajectory scoring prediction (each column shares the same task; every row uses the same trajectory); Middle: promising results testing on real-world data (from left to right: input, affordance prediction, trajectory proposals); Right: real-robot experiment. |
National Natural Science Foundation of China —Youth Science Fund (No.62006006): Learning Visual Prediction of Interactive Physical Scenes using Unlabelled Videos. Leonidas and Kaichun are supported by a grant from the Toyota Research Institute University 2.0 program, NSF grant IIS-1763268, and a Vannevar Bush faculty fellowship. We would like to thank Yourong Zhang for setting up ROS environment and helping in real robot experiments, Jiaqi Ke for designing and doing heuristic experiments.