It is essential yet challenging for future home-assistant robots to understand and manipulate diverse 3D objects in daily human environments. Towards building scalable systems that can perform diverse manipulation tasks over various 3D shapes, recent works have advocated and demonstrated promising results learning visual actionable affordance, which labels every point over the input 3D geometry with an action likelihood of accomplishing the downstream task (e.g., pushing or picking-up). However, these works only studied single-gripper manipulation tasks, yet many real-world tasks require two hands to achieve collaboratively. In this work, we propose a novel learning framework, DualAfford, to learn collaborative affordance for dual-gripper manipulation tasks. The core design of the approach is to reduce the quadratic problem for two grippers into two disentangled yet inter- connected subtasks for efficient learning. Using the large-scale PartNet-Mobility and ShapeNet datasets, we set up four benchmark tasks for dual-gripper manipulation. Experiments prove the effectiveness and superiority of our method over three baselines.
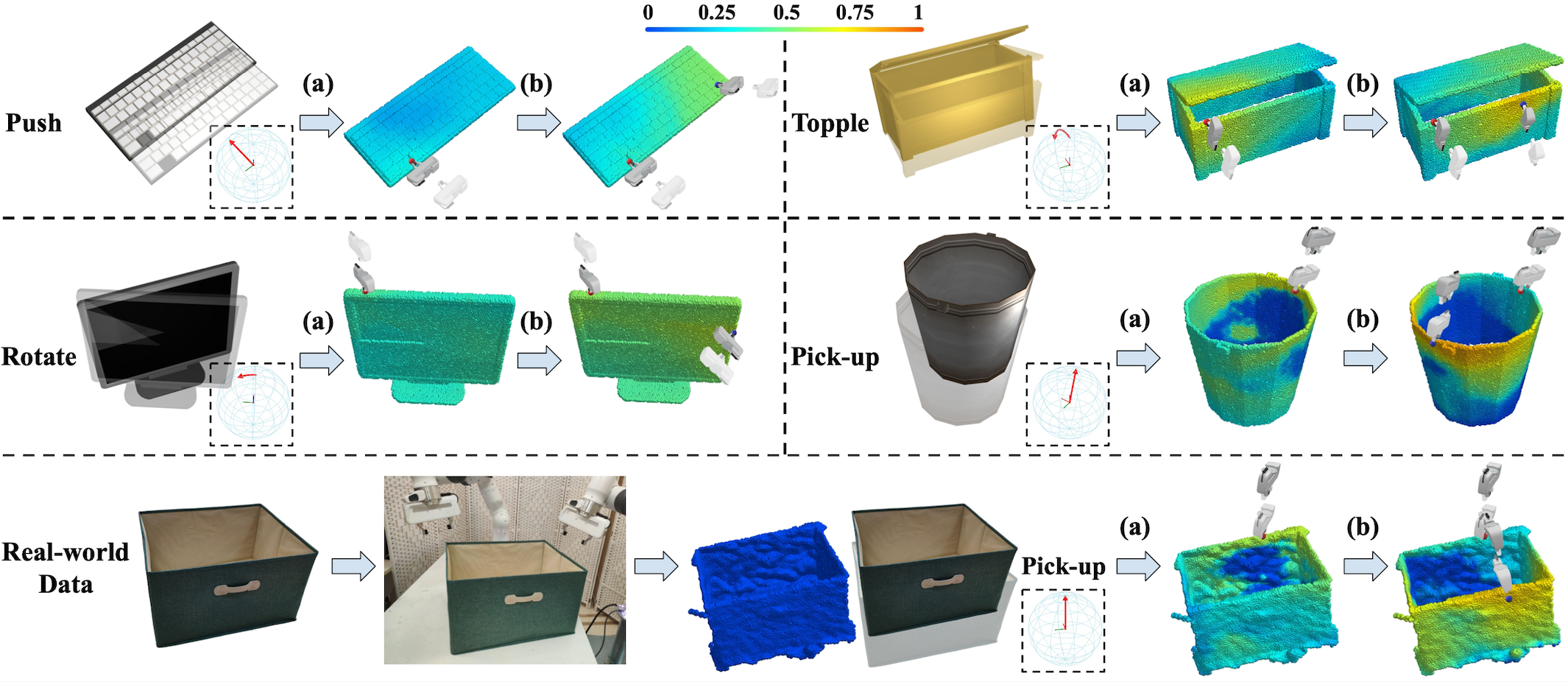
Figure 1. Given different shapes and manipulation tasks (e.g., pushing the keyboard in the direction indicated by the red arrow), our proposed DualAfford framework predicts dual collaborative visual actionable affordance and gripper orientations. The prediction for the second gripper (b) is dependent on the first (a). We can directly apply our network to real-world data. |
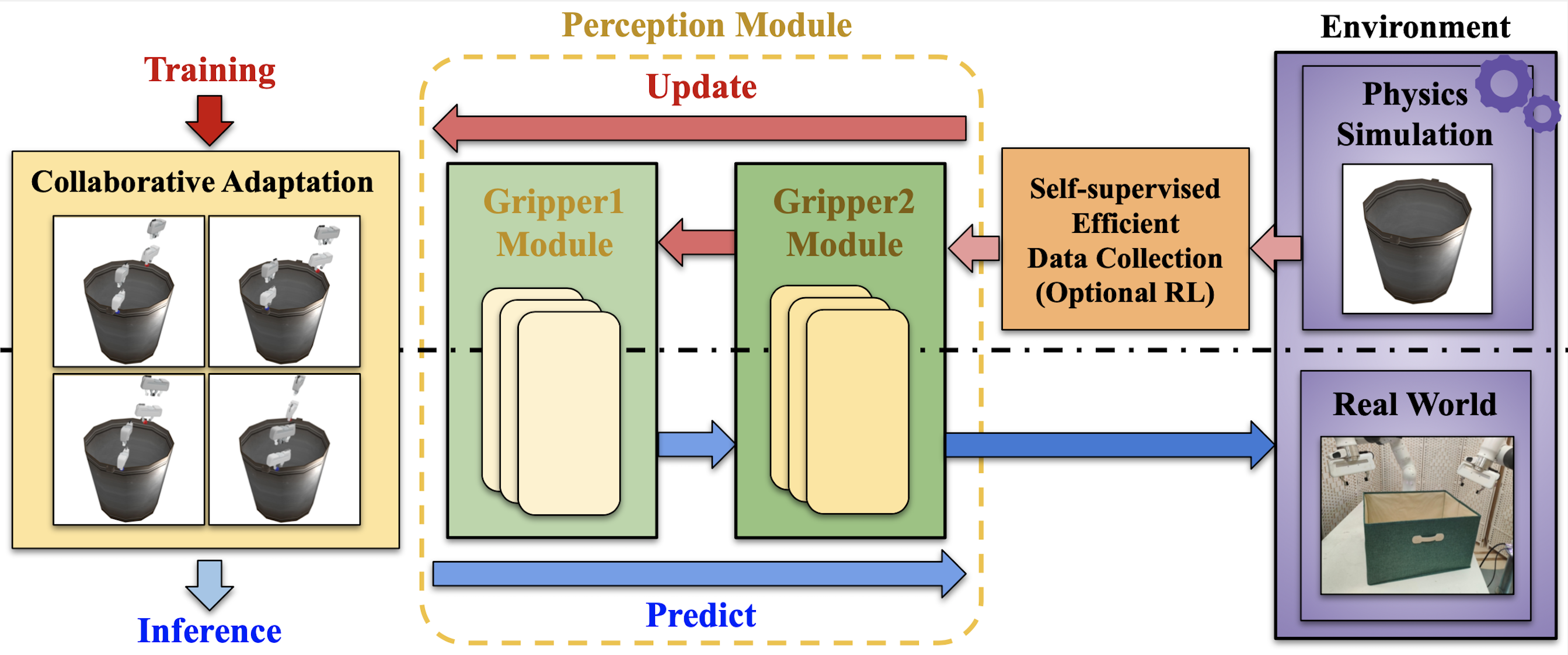
Figure 2. Our proposed DualAfford framework, first collects interaction data points in physics simulation, then uses them to train the Perception Module, which contains the First Gripper Module and the Second Gripper Module, and further enhances the cooperation between two grippers through the Collaborative Adaption procedure. The training and the inference procedures, as respectively indicated by the red and blue arrows, share the same architecture but with opposite dataflow directions. |
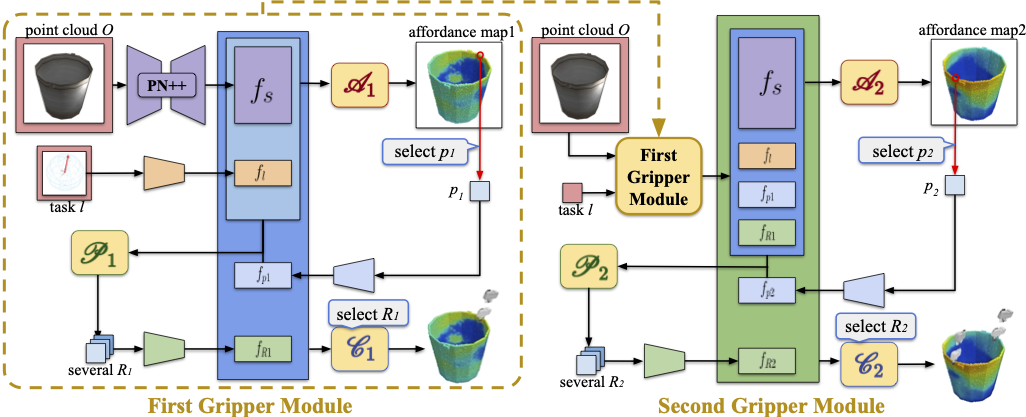
Figure 3. Architecture details of the Perception Module. Given a 3D partial scan and a specific select task, our network sequentially predicts the first and second grippers’ affordance maps and manipulation actions in a conditional manner. Each gripper module is composed of 1) an Affordance Network A indicating where to interact; 2) a Proposal Network P suggesting how to interact; 3) a Critic Network C evaluating the success likelihood of an interaction. |
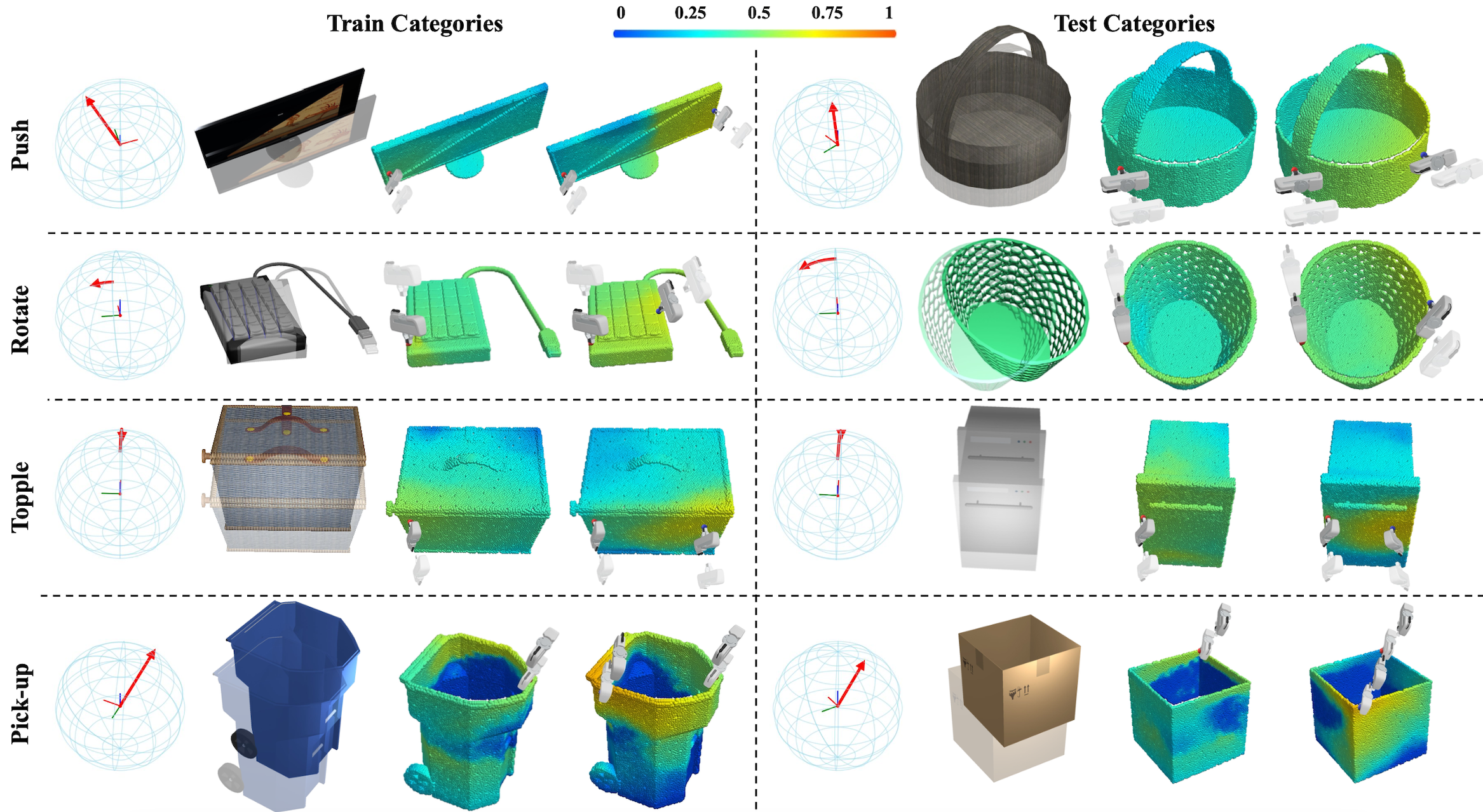
Figure 4. Qualitative results of Affordance Networks. In each block, we respectively show (1) task represented by a red arrow, (2) object which should be moved from transparent to solid, (3) the first affordance map predicted by A1, (4) the second affordance map predicted by A2 conditioned on the first action. Left shapes are from training categories, while right shapes are from unseen categories. |
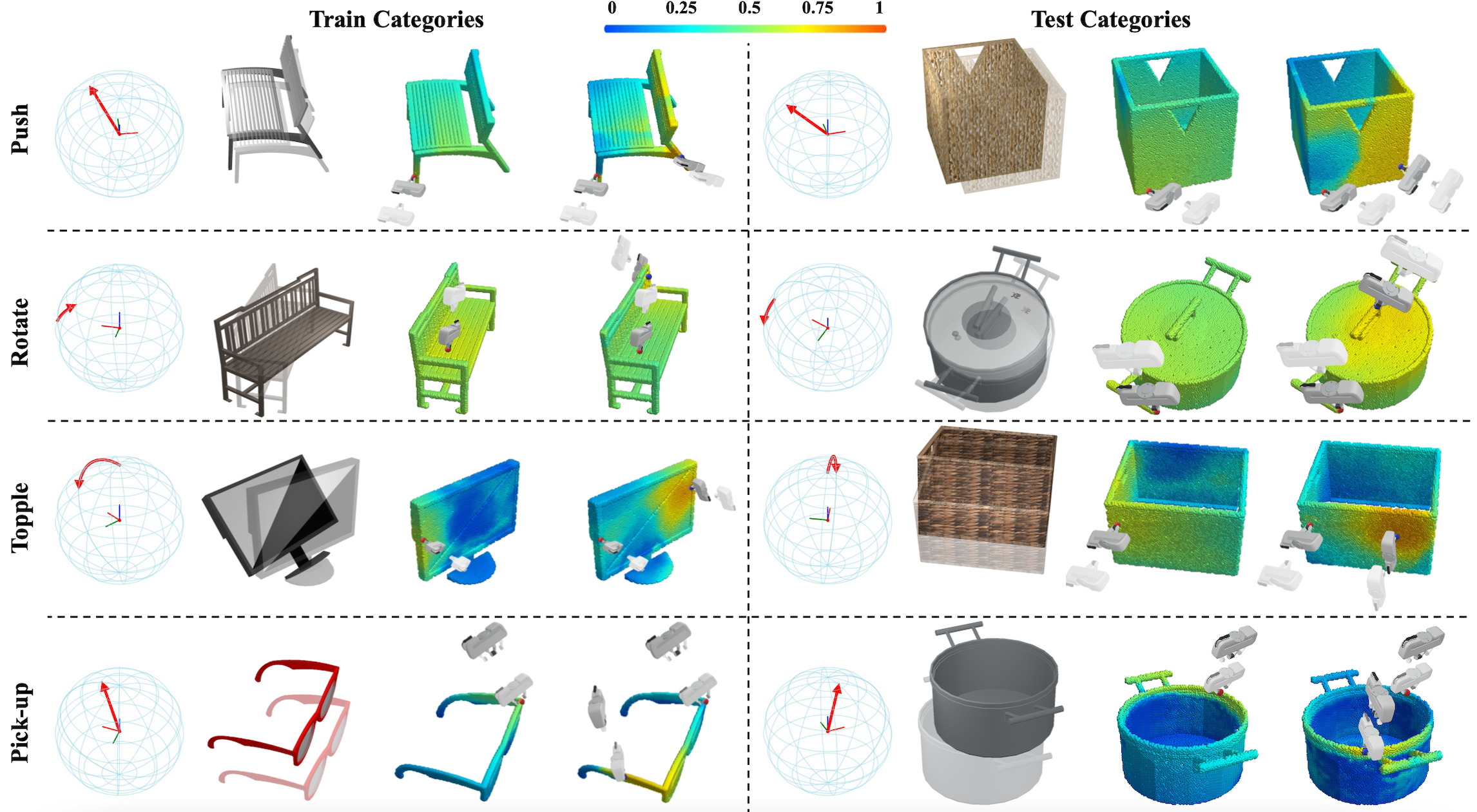
Figure 5. The per-point action scores predicted by Critic Networks C1 and C2. In each result block, from left to right, we show the task, the input shape, the per-point success likelihood predicted by C1 given the first gripper orientation, and the per-point success likelihood predicted by C2 given the second gripper orientation, conditioned on the first gripper’s action. |
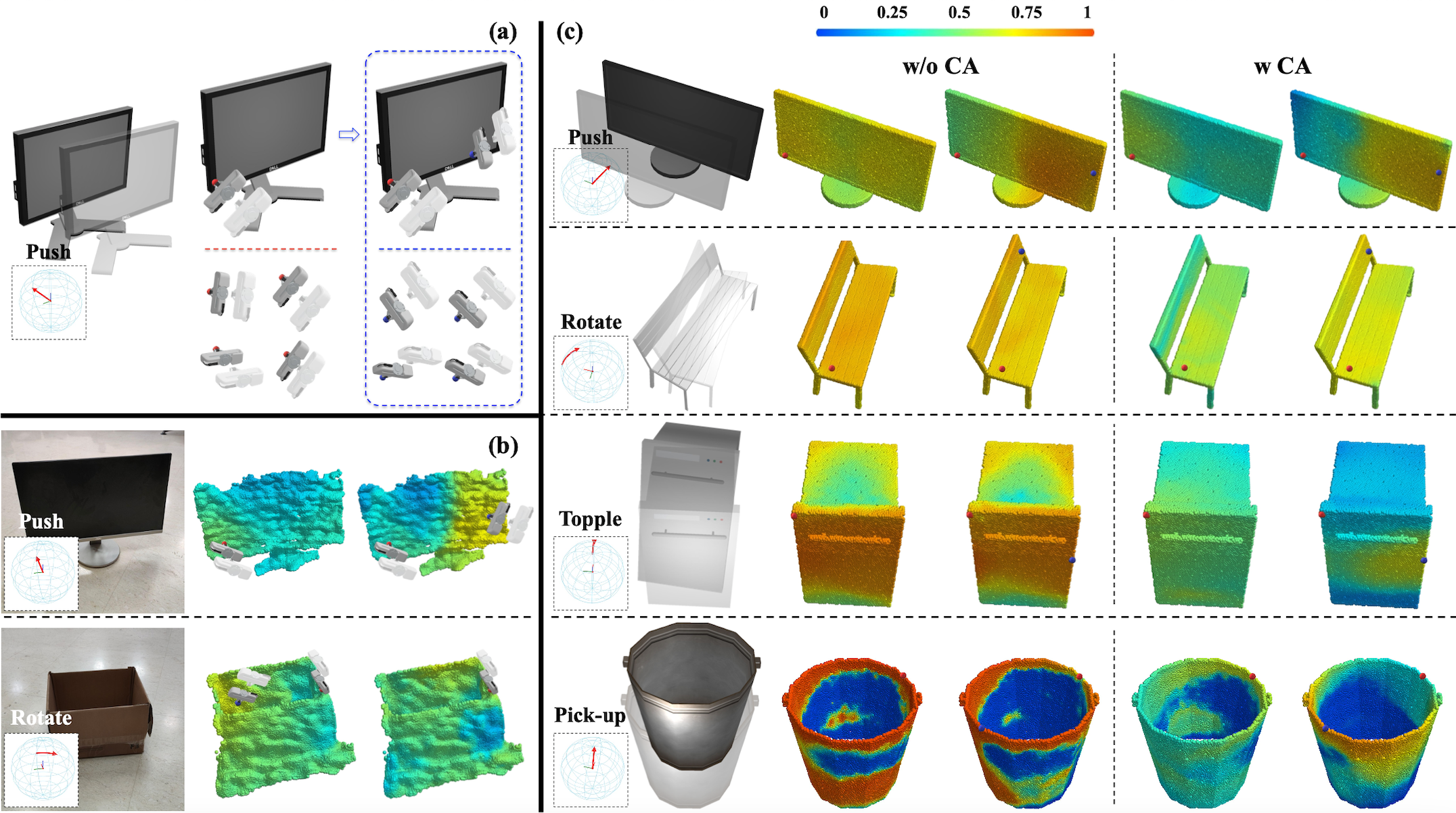
Figure 6. (a) The diverse and collaborative actions proposed by the Proposal Networks P1 and P2. (b) The promising results testing on real-world data. (c) The actionable affordance maps of the ablated version that removes the Collaborative Adaptation procedure (left) and ours (right). |
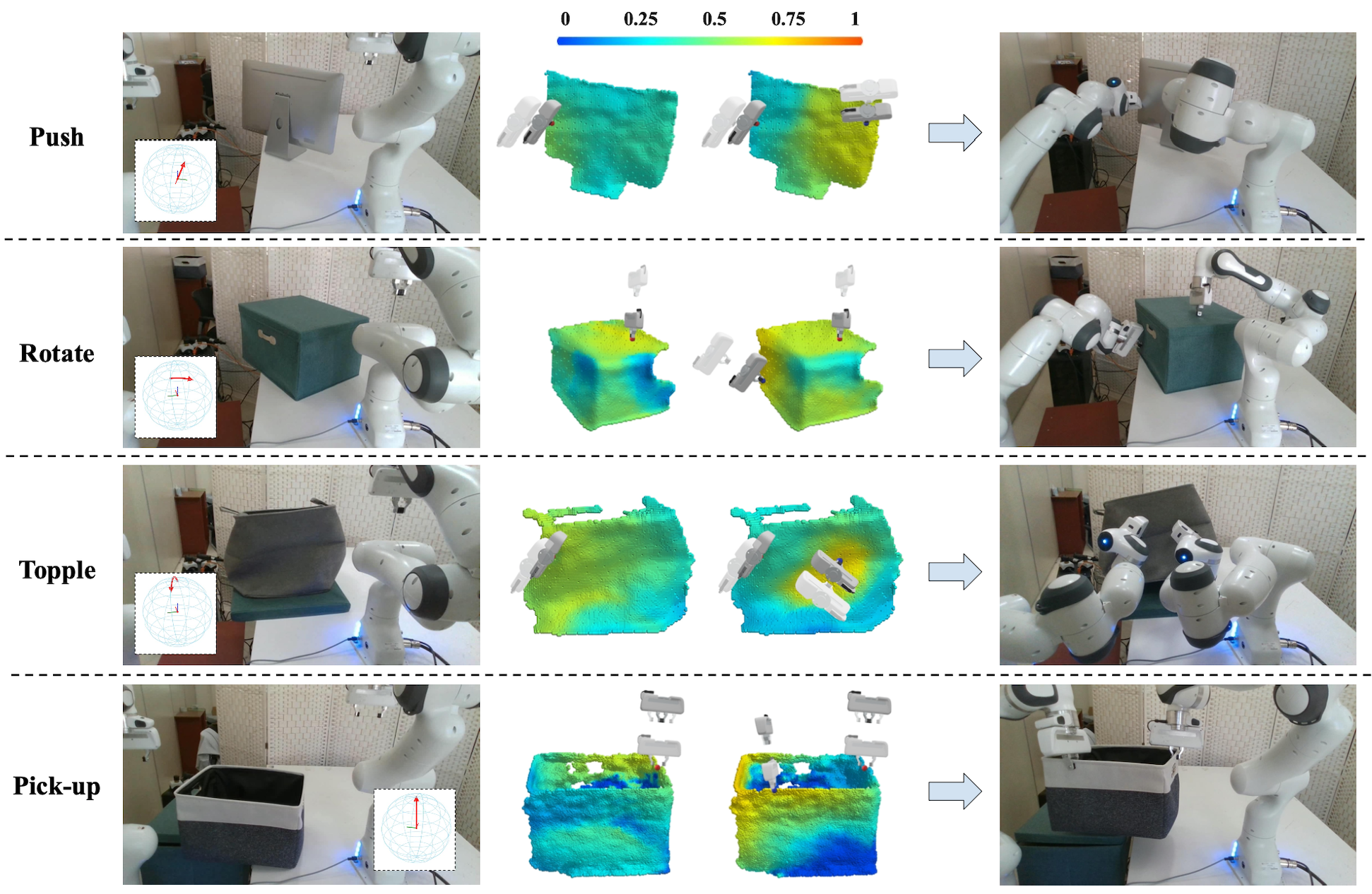
Figure 7. We present some promising results by directly testing our model on real-world scans. In each block, from left to right, we respectively show the task represented by a red arrow, the input shape, the actionability heatmap predicted by network A1, and the actionability heatmap predicted by network A2 conditioned on the action of the first gripper. Please check our video for more results. |
@inproceedings{zhao2023dualafford,
title={DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Manipulation},
author={Yan Zhao and Ruihai Wu and Zhehuan Chen and Yourong Zhang and Qingnan Fan and Kaichun Mo and Hao Dong},
booktitle={International Conference on Learning Representations},
year={2023},
}
If you have any questions, please feel free to contact Yan Shen (Yan Zhao) at yan790_at_pku_edu_cn.
(The previous email address zhaoyan790_at_pku_edu_cn is no longer active.)