Understanding and manipulating deformable objects (e.g., ropes and fabrics) is an essential yet challenging task with broad applications. Difficulties come from complex states and dynamics, diverse configurations and high-dimensional action space of deformable objects. Besides, the manipulation tasks usually require multiple steps to accomplish, and greedy policies may easily lead to local optimal states. Existing studies usually tackle this problem using reinforcement learning or imitating expert demonstrations, with limitations in modeling complex states or requiring hand-crafted expert policies. In this paper, we study deformable object manipulation using dense visual affordance, with generalization towards diverse states, and propose a novel kind of foresightful dense affordance, which avoids local optima by estimating states' values for long-term manipulation. We propose a framework for learning this representation, with novel designs such as multi-stage stable learning and efficient self-supervised data collection without experts. Experiments demonstrate the superiority of our proposed foresightful dense affordance.
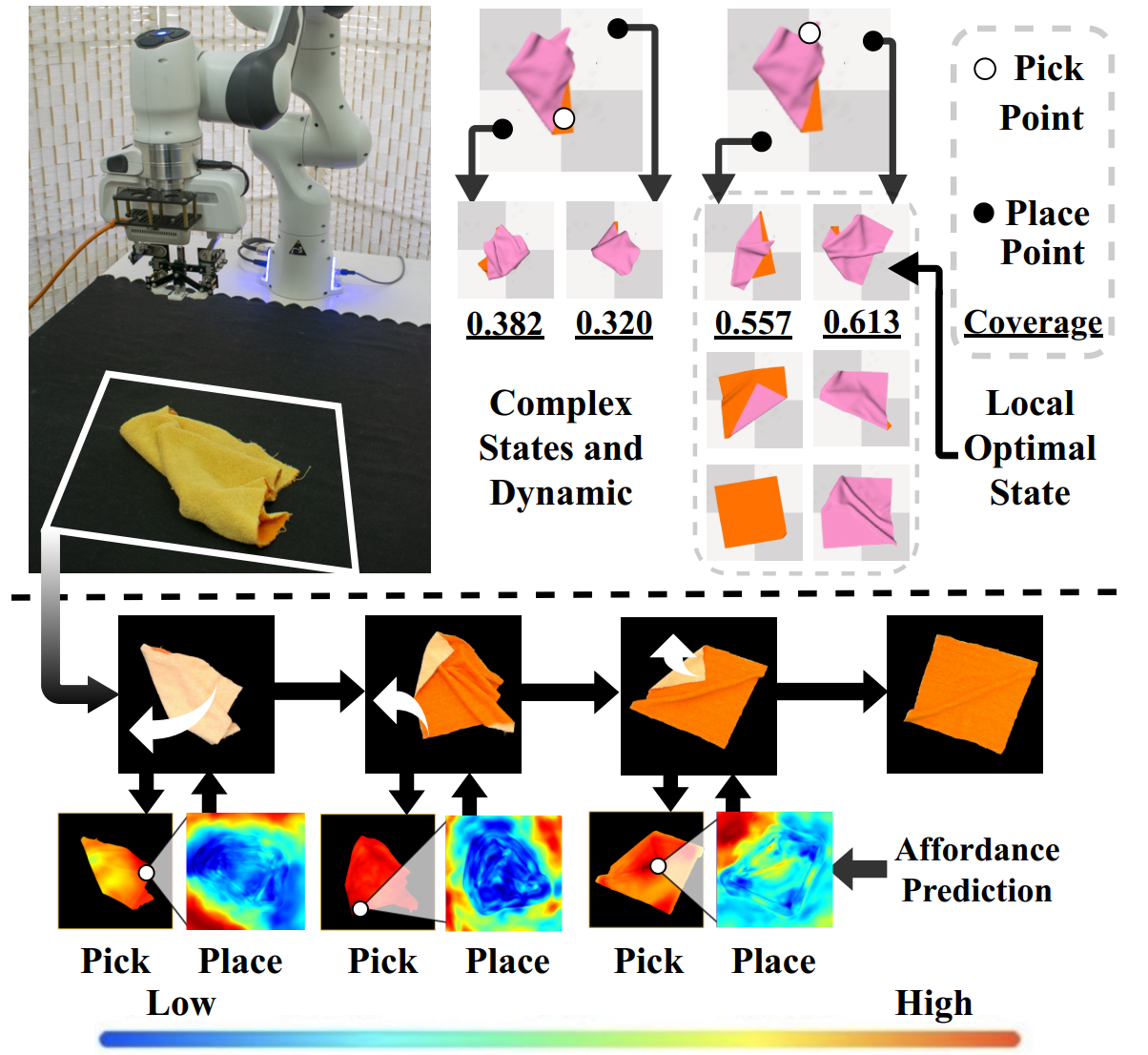
Figure 1. Deformable Object Manipulation has many difficulties. 1) It requires multiple steps to complete. 2) Most actions can hardly facilitate tasks, for the exceptionally complex states and dynamics. 3) Many local optimal states are temporarily closer to the target, but making following actions harder to coordinate for the whole task. We propose to learn Foresightful Dense Visual Affordance aware of future actions to avoid local optima for deformable object manipulation, with real-world implementations. |
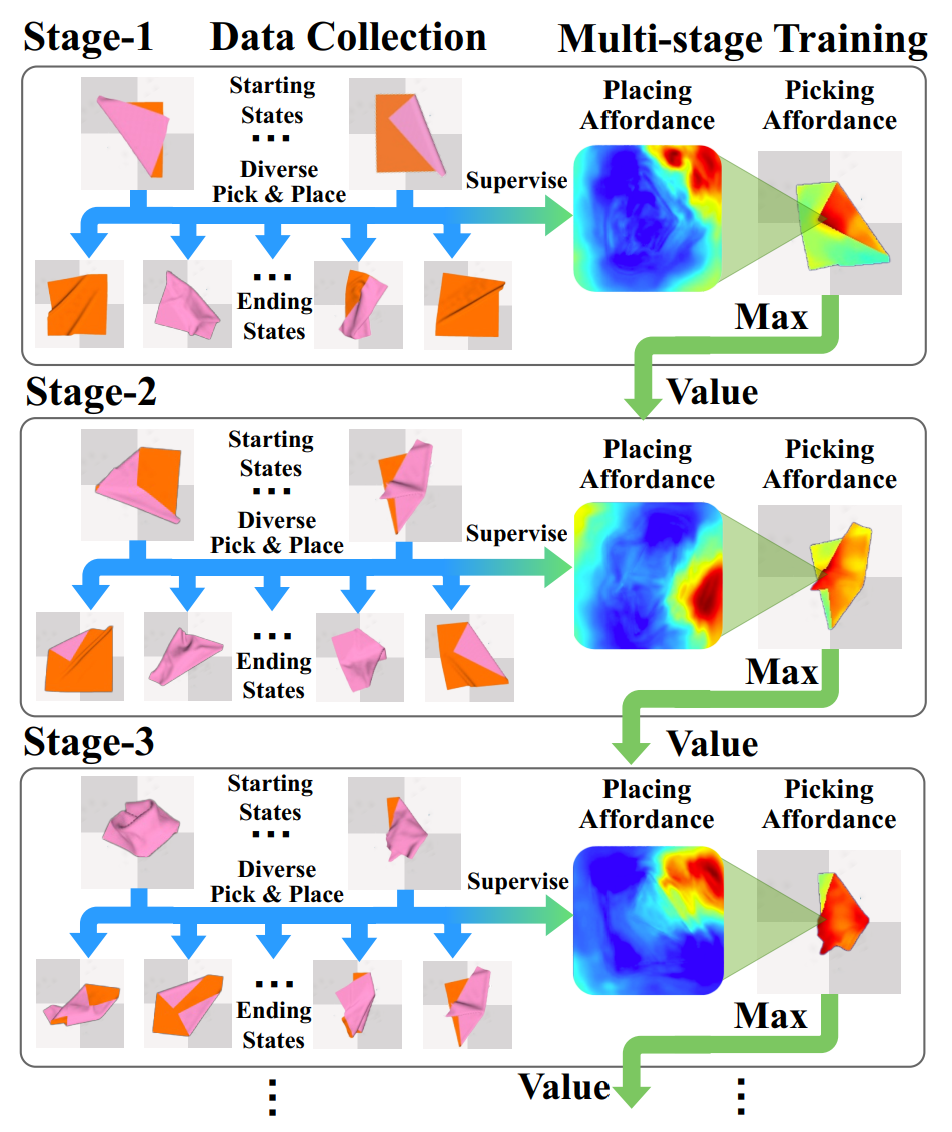
Figure 2. Our proposed framework learns dense picking and placing affordance for deformable object manipulation (e.g., Unfolding Cloth). We collect multi-stage interaction data efficiently (Left) and learn proposed affordance stably in a multi-stage schema (Right) in the reversed task accomplishment order, from states close to the target to complex states. |
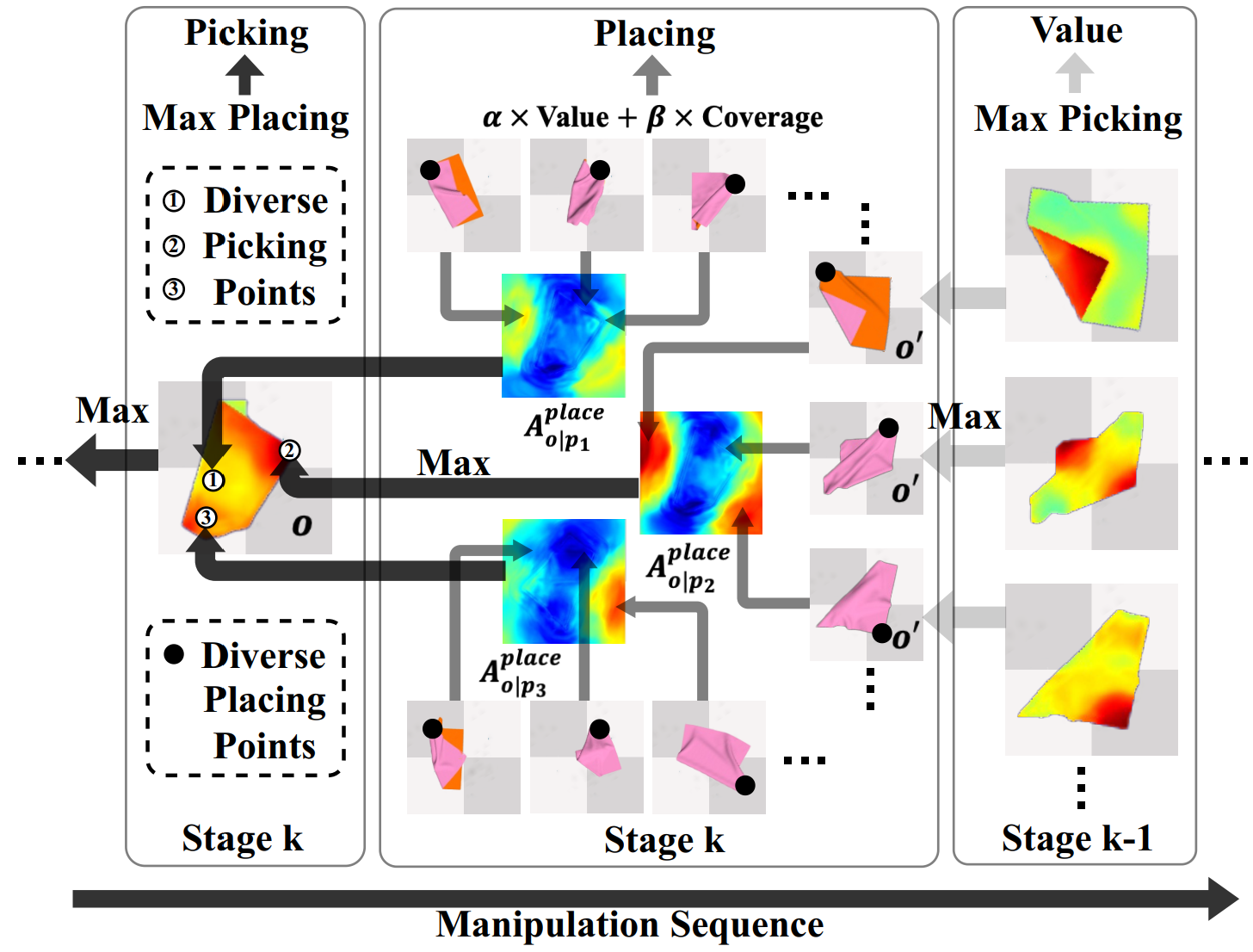
Figure 3. Learning placing and picking affordance with state ‘value’s for the future. Left to Right: The bottom black arrow indicates the manipulation (inference) order. Right to Left: Arrow flows show dependencies among placing affordance, picking affordance and ‘value’s. Given observation o, we select 3 picking points p1 p2 p3, and show how to supervise corresponding placing affordance Aplace o|p1 Aplace o|p2 Aplace o|p3 , and how to supervise Apick o on p1 p2 p3 using computed corresponding placing affordance. |
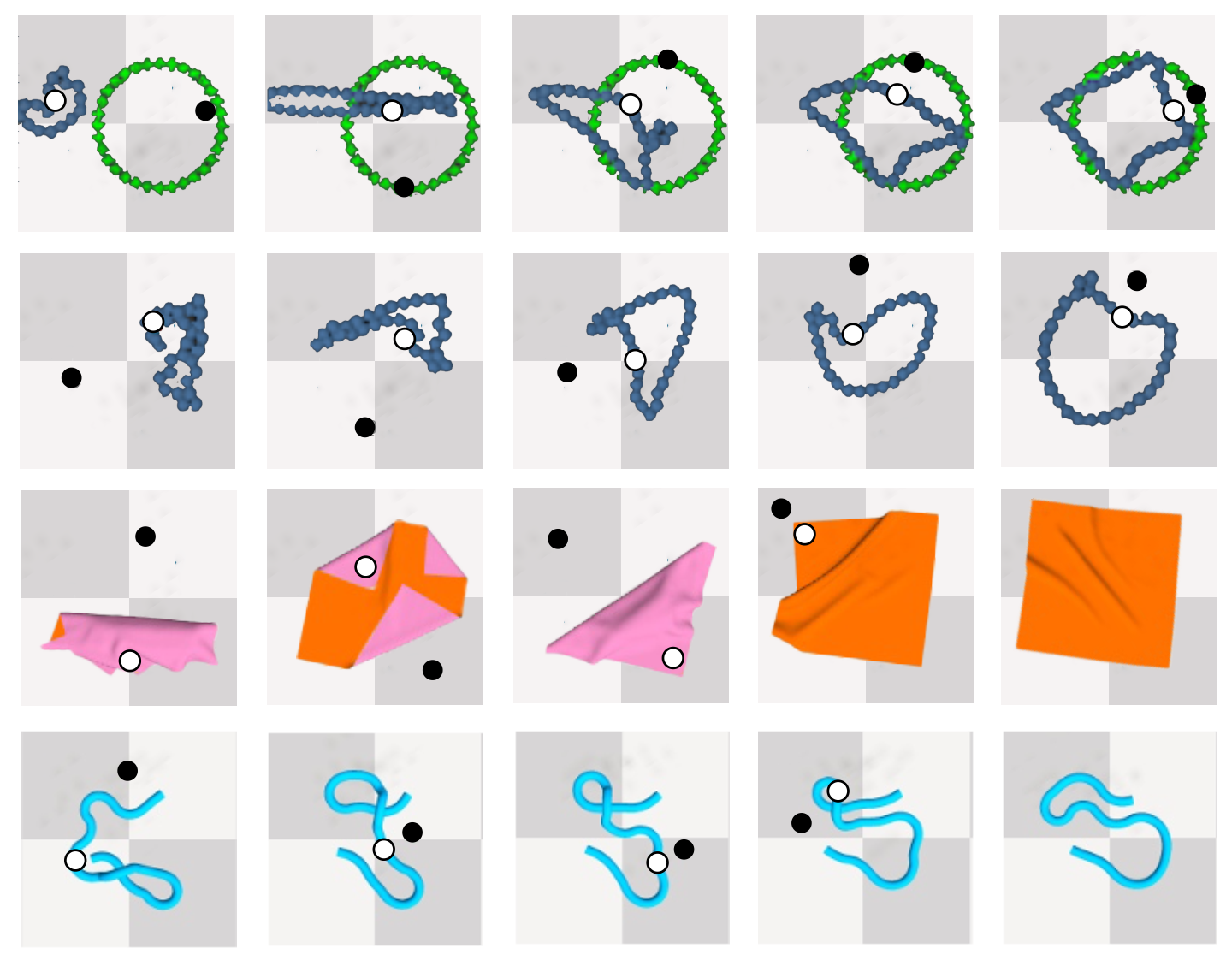
Figure 4. Example action sequences for cable-ring, cable-ringnotarget, SpreadCloth and RopeConfiguration. White point denotes picking and black point denotes placing. |
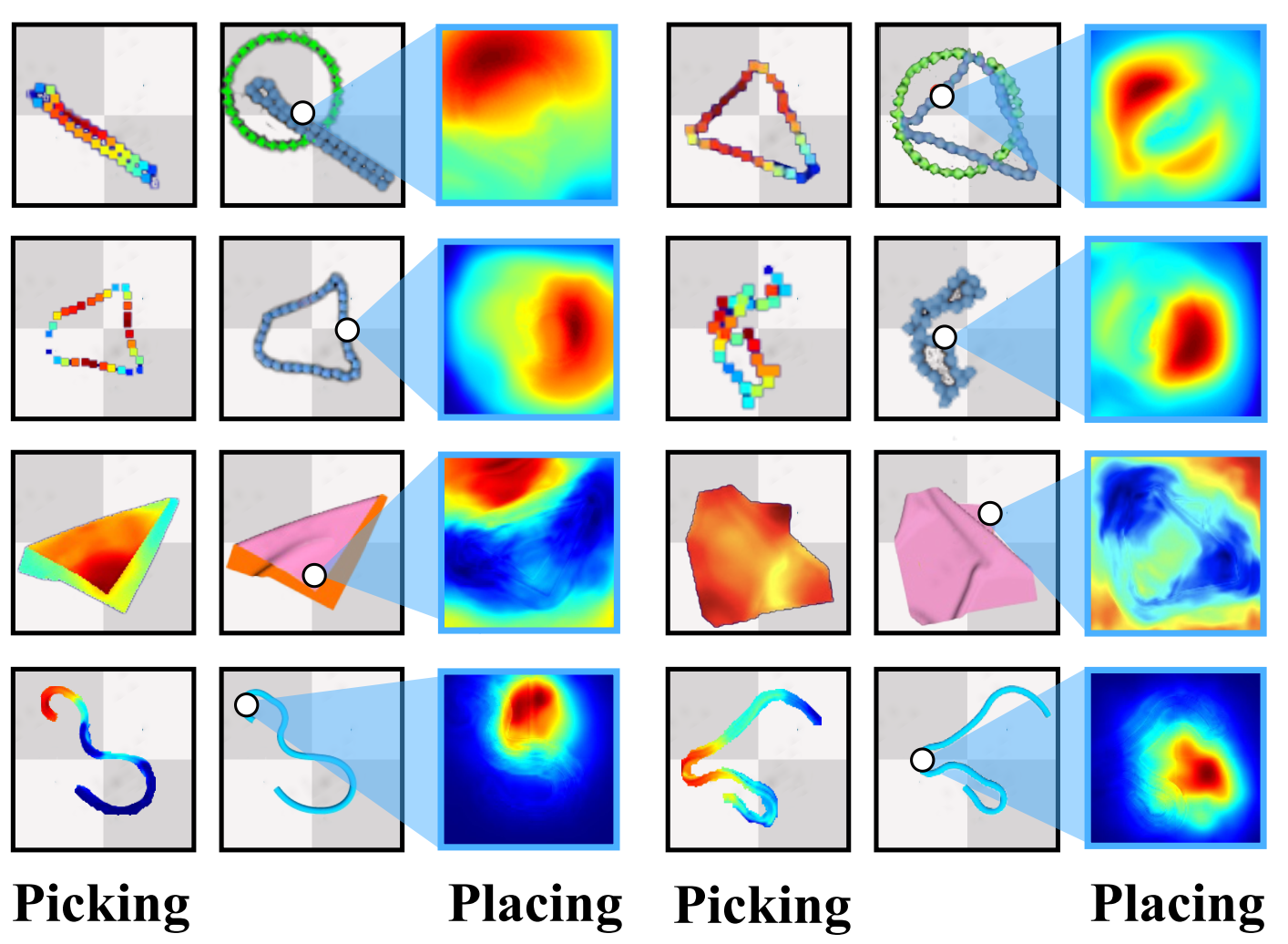
Figure 5. Picking and placing affordance. Each row contains two (picking affordance, observation with ppick, placing affordance) tuples for a task. ppick is selected by picking affordance. Higher color temperature means higher affordance. |
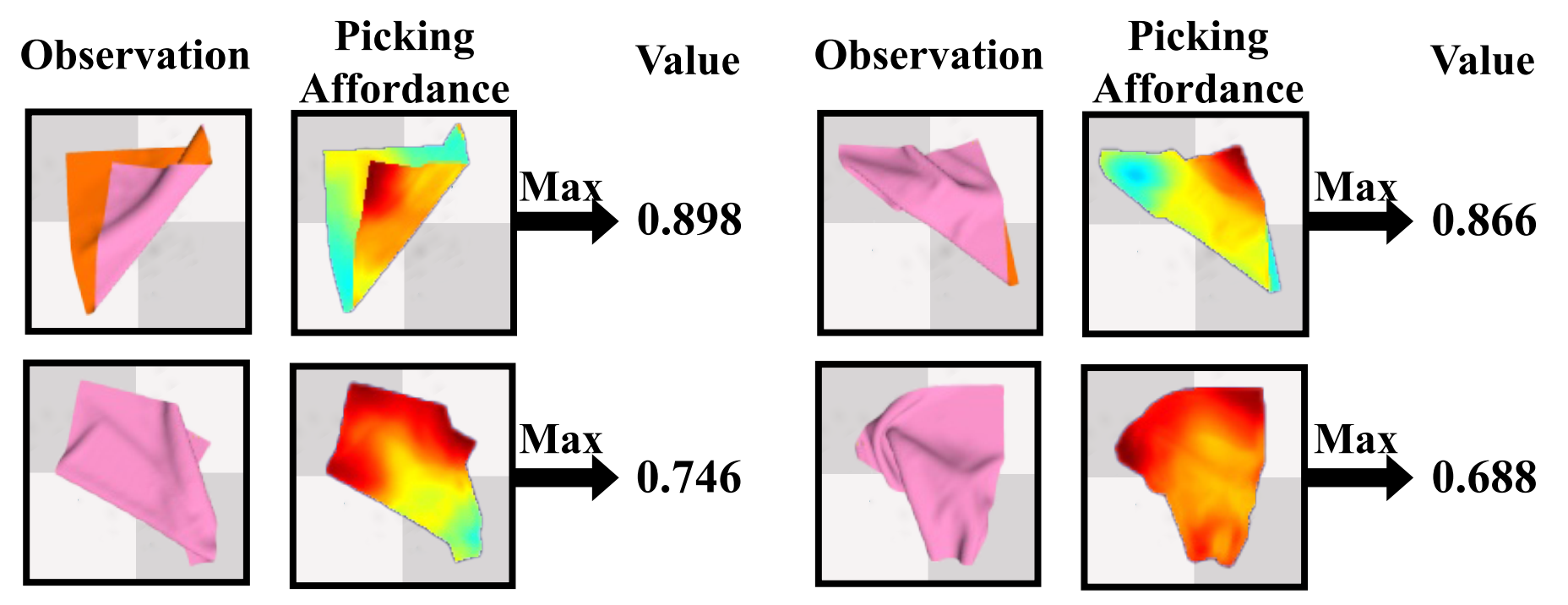
Figure 6. Visualization of ‘value’ shows that some states with closer distances to the target (e.g., larger area) may not have higher ‘value’, as these states are hard for future actions to fulfill the task. |
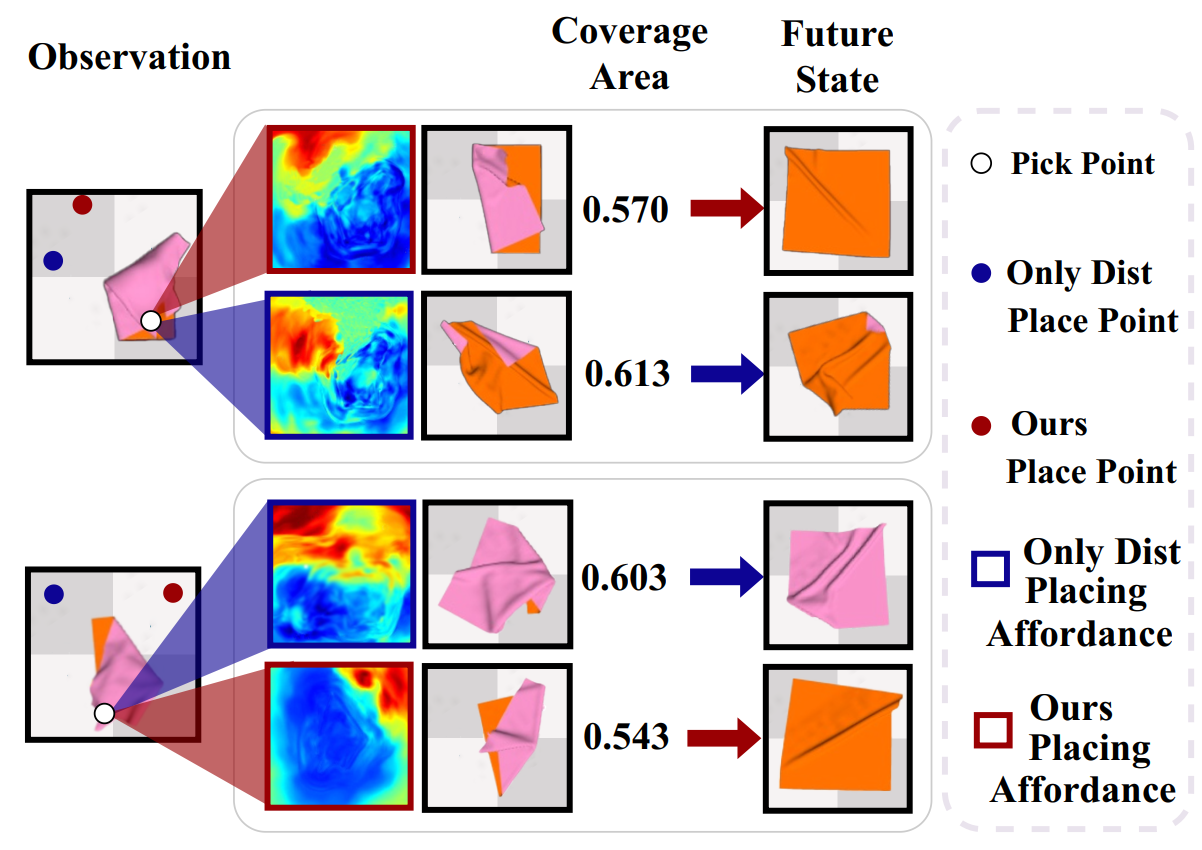
Figure 7. Placing affordance trained using ‘value’ supervision (red) and only using the greedy direct distance (blue). |
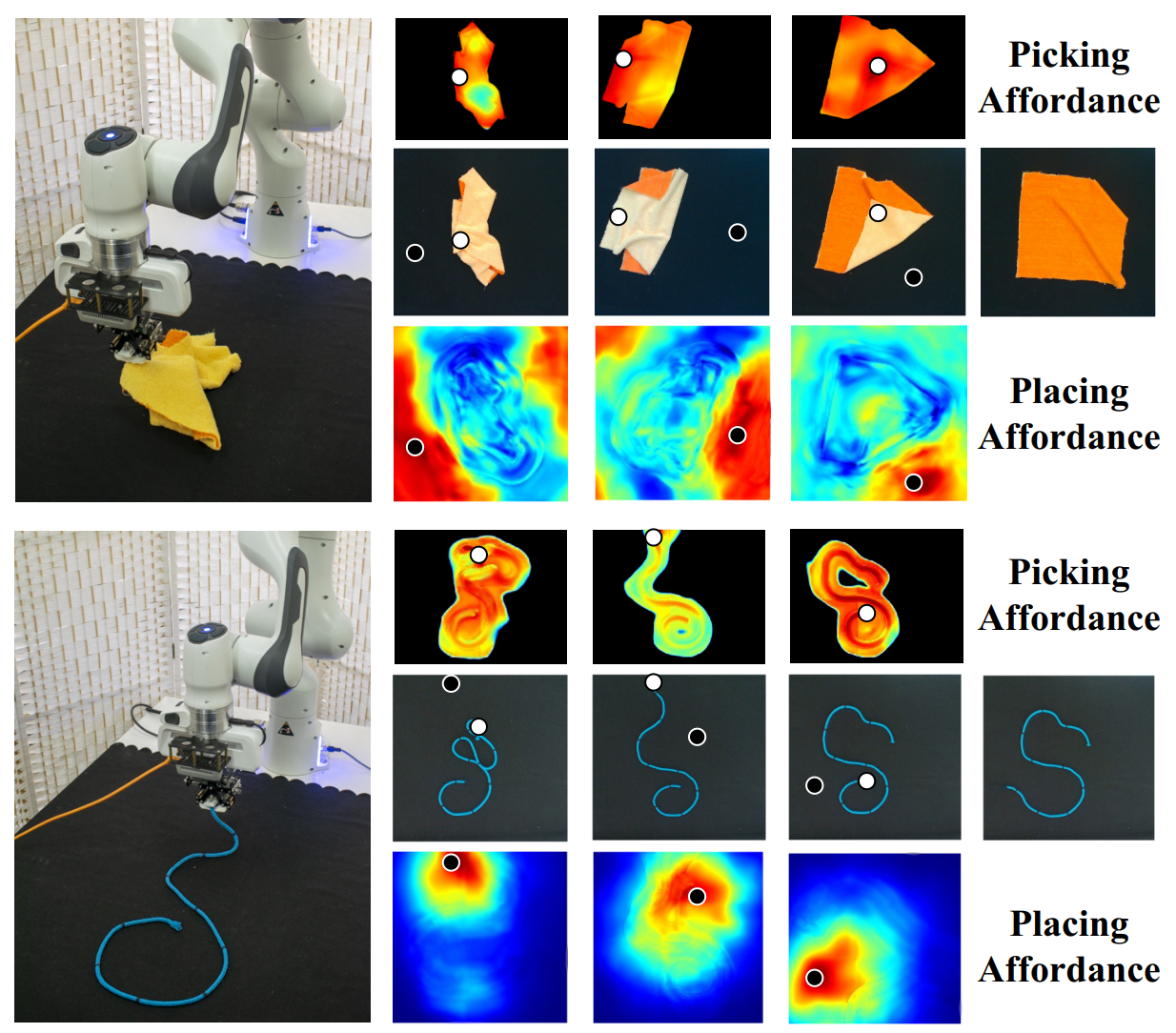
Figure 8. Examples of real-world manipulation trajectories guided by picking and placing affordance. |
@inproceedings{wu2023learning,
title={Learning Foresightful Dense Visual Affordance for Deformable Object Manipulation},
author={Wu, Ruihai and Ning, Chuanruo and Dong, Hao},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2023}
}
If you have any questions, please feel free to contact Ruihai Wu at wuruihai_at_pku_edu_cn and Chuanruo Ning at chuanruo_at_stu_pku_edu_cn.