Perceiving and interacting with 3D articulated objects, such as cabinets, doors, and faucets, pose particular challenges for future home-assistant robots performing daily tasks in human environments. Besides parsing the articulated parts and joint parameters, researchers recently advocate learning manipulation affordance over the input shape geometry which is more task-aware and geometrically fine-grained. However, taking only passive observations as inputs, these methods ignore many hidden but important kinematic constraints (e.g., joint location and limits) and dynamic factors (e.g., joint friction and restitution), therefore losing significant accuracy for test cases with such uncertainties. In this paper, we propose a novel framework, named AdaAfford, that learns to perform very few test-time interactions for quickly adapting the affordance priors to more accurate instance-specific posteriors. We conduct large-scale experiments using the PartNet-Mobility dataset and prove that our system performs better than baselines. We will release our code and data upon paper acceptance.
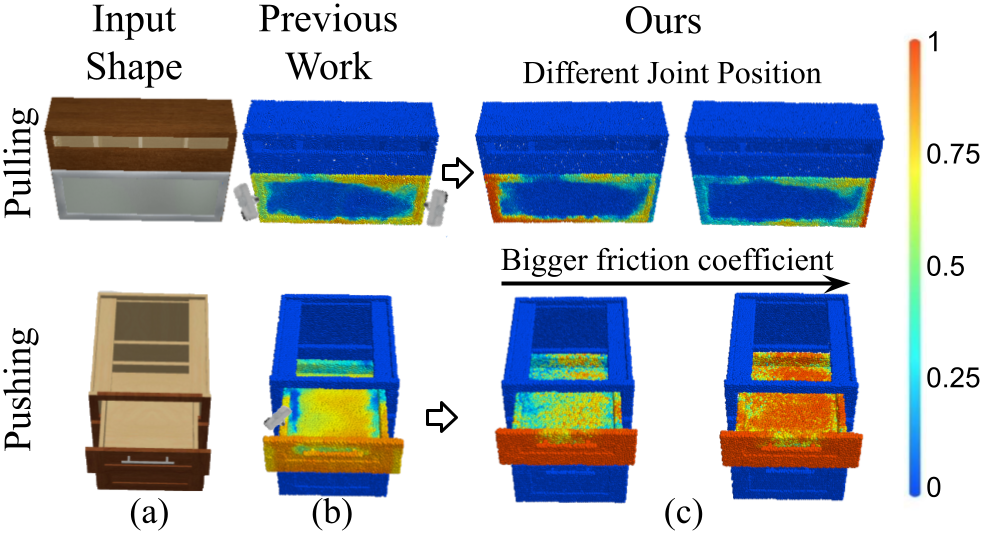
Figure 1. For robotic manipulation over 3D articulated objects (a), past works have demonstrated the usefulness of per-point manipulation affordance (b). However, only observing static visual inputs passively, these systems suffer from intrinsic ambiguities over kinematic constraints. Our AdaAfford framework reduces such uncertainties via interactions and quickly adapts instance-specific affordance posteriors (c). |
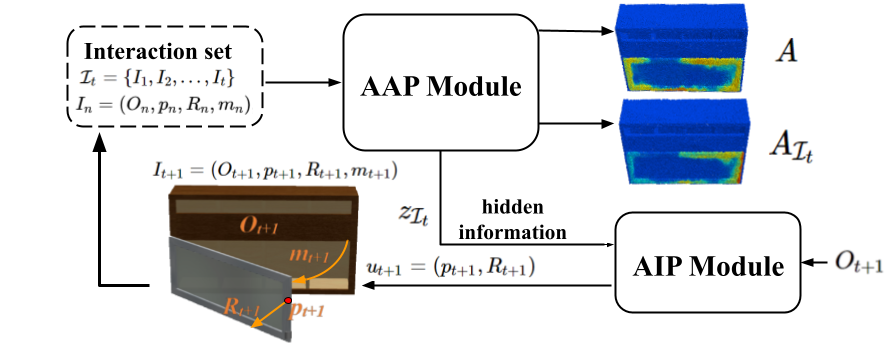
Figure 2. Test-time overview. Our proposed AdaAfford framework primarily consists of two modules – an Adaptive Interaction Proposal module and an Adaptive Affordance Prediction module. While the AIP module learns a greedy yet effective strategy for sequentially proposing the few-shot test-time interactions, the AAP module is trained to adapt the affordance predictions. Please check the main paper for more technical details. |
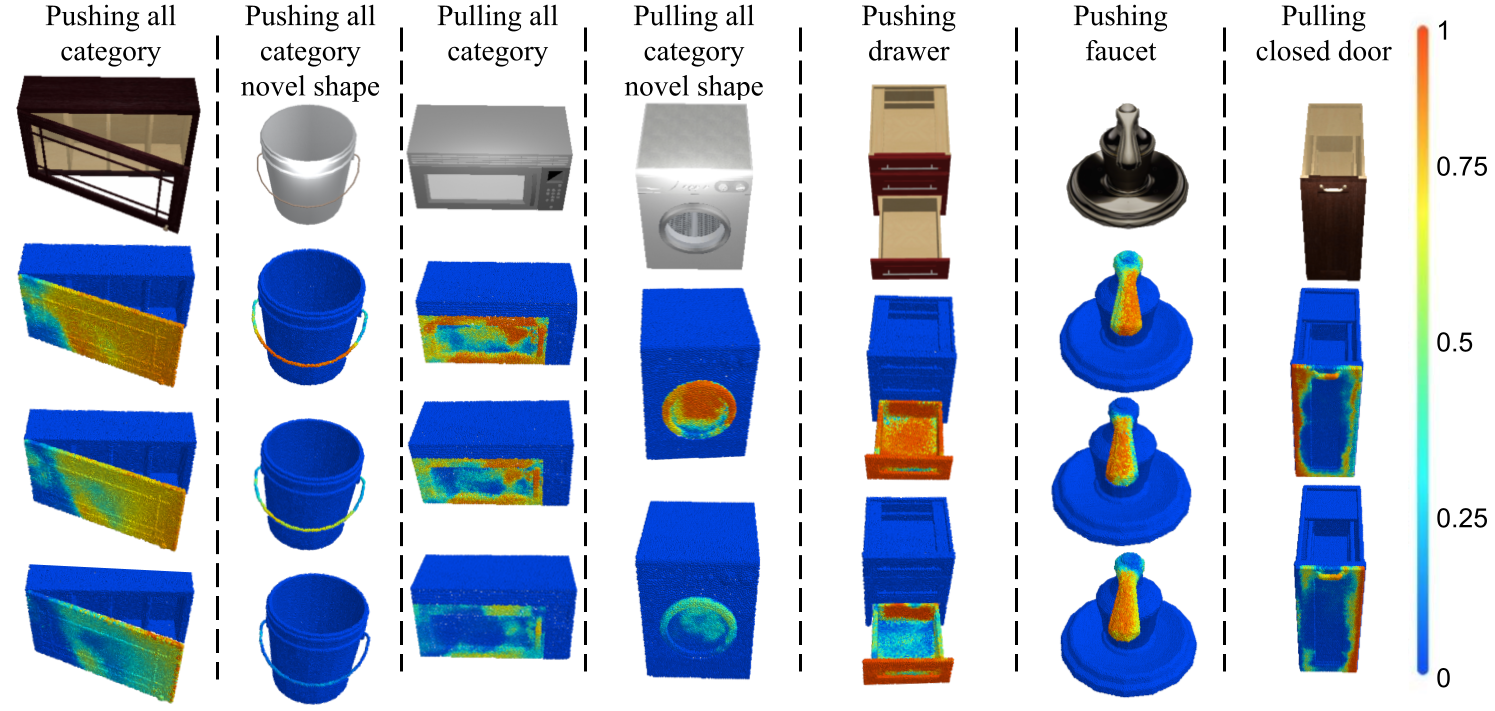
Figure 3. Example results of adapted affordance predictions given by AAP module under different kinematic and dynamic parameters. The first five columns show the adapted affordance prediction conditioned on increasing joint friction (the first and second columns), part mass (the third column), and friction coefficient on object surface (the fourth and fifth columns). The last two columns respectively show the influence of different rotating directions (i.e., joint limits) and joint axis locations. |
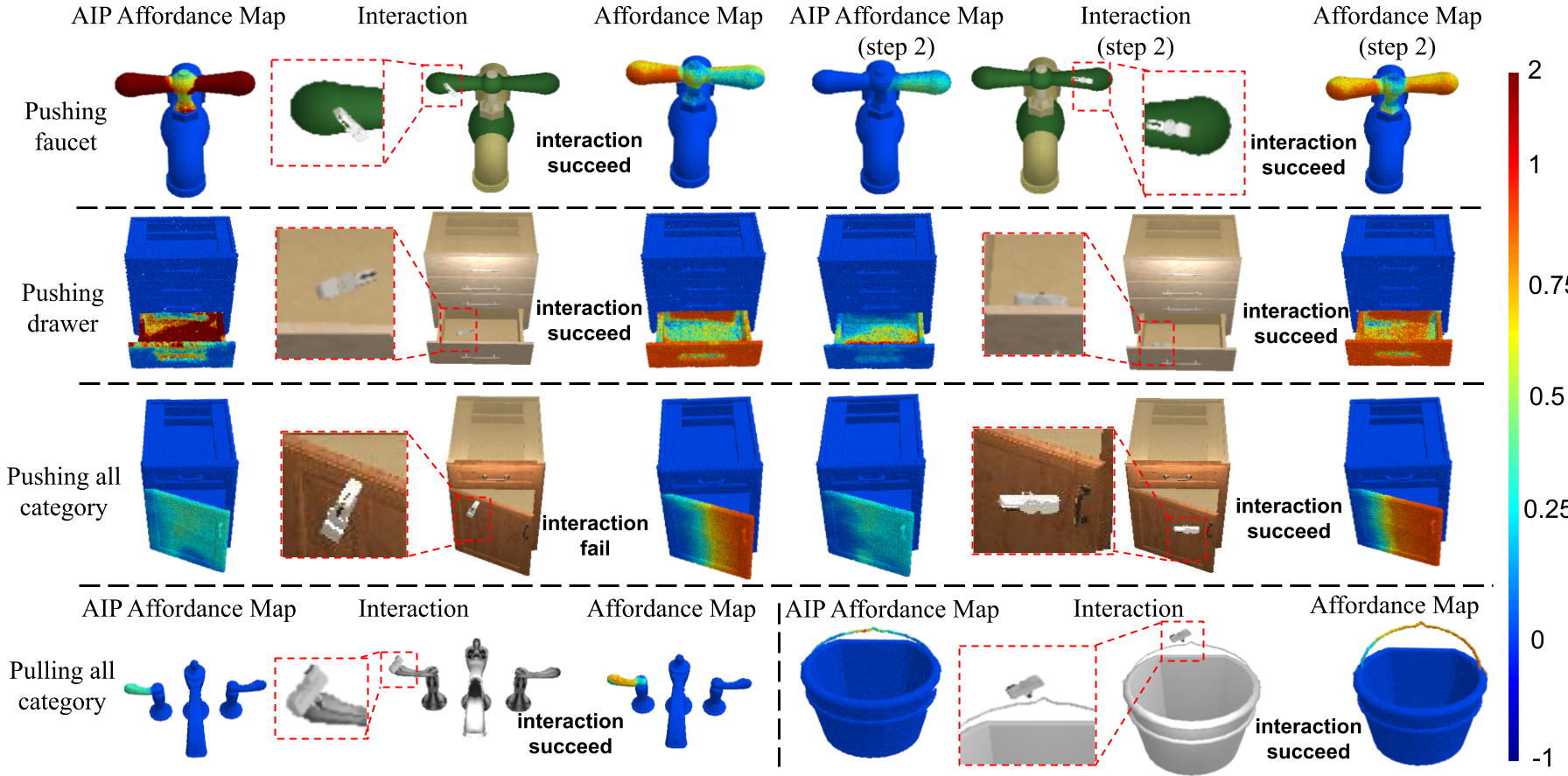
Figure 4. Example results for the interactions proposed by the AIP module and the corresponding AIP affordance map predictions. In the first three rows, we show the initial and the second AIP affordance maps, the corresponding proposed interactions, and the posterior affordance map predictions. In the last row, we present two more examples that only one interaction is needed. From these results, our AIP module successfully proposes reasonable interactions for querying useful hidden information. |

Figure 5. Real-robot experiment on pulling open a closed door in the real world. We show the AIP affordance map predictions, the AIP proposed interactions, and the AAP posterior predictions, for two interaction trials. The results show that our work could reasonably generalize to real-world scenarios. |
National Natural Science Foundation of China —Youth Science Fund (No.62006006). Leonidas and Kaichun were supported by the Toyota Research Institute (TRI) University 2.0 program, NSF grant IIS-1763268, a Vannevar Bush Faculty Fellowship, and a gift from the Amazon Research Awards program.The Toyota Research Institute University 2.0 program. (Toyota Research Institute ("TRI") provided funds to assist the authors with their research but this article solely reflects the opinions and conclusions of its authors and not TRI or any other Toyota entity).